2. PostgreSQL CDC specifics
WALking the line
ACID-compliant SQL transactions have been a part of PostgreSQL for a long time. A fundamental concept accompanying transactions is the requirement to log them before they are committed.
Each database vendor has their own way of logging transactions and PostgreSQL makes use of a data structure called a write-ahead log (or WAL for short).
The main idea behind WAL is that changes to data files (where tables and indexes reside) must be written only after the corresponding log records have been flushed to permanent storage. This way, PostgreSQL avoids excessive disk writes for every transaction commit; instead, user data changes can be flushed efficiently in batches. Also, in case of a server failure, missing user data changes can be recovered from the WAL once the server is back online.
So far, we know that WAL serves two main purposes: disaster recovery and disk utilization optimisation. But there’s another use case for WALs that has seen a recent rise in popularity. Yes, you’ve guessed it: CDC! Among many other things, WAL logs already contain all the events we need: inserts, updates and deletes.
If you’re interested in reading up on how WALs work internally, you can either consult the official PostgreSQL documentation or a phenomenal article series by Hironobu Suzuki which goes in the most exhaustive detail on how WALs work.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
$ sudo /usr/lib/postgresql/16/bin/pg_waldump .../16/main/pg_wal/000000010000000000000006 | tail -n 20
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064A7868, prev 0/064A7840, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064A78A0, prev 0/064A7868, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/064A78D8, prev 0/064A78A0, desc: CHECKPOINT_ONLINE redo 0/64A78A0; tli 1; prev tli 1; fpw true; xid 0:6476; oid 161285; multi 1; offset 0; oldest xid 722 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 6476; online
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064A7950, prev 0/064A78D8, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: Heap2 len (rec/tot): 60/ 7532, tx: 0, lsn: 0/064A7988, prev 0/064A7950, desc: PRUNE snapshotConflictHorizon: 6457, nredirected: 0, ndead: 3, blkref #0: rel 1663/27783/2608 blk 38 FPW
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064A9710, prev 0/064A7988, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: Heap2 len (rec/tot): 60/ 5920, tx: 0, lsn: 0/064A9748, prev 0/064A9710, desc: PRUNE snapshotConflictHorizon: 6409, nredirected: 0, ndead: 16, blkref #0: rel 1663/5/1249 blk 17 FPW
rmgr: Heap2 len (rec/tot): 60/ 7848, tx: 0, lsn: 0/064AAE80, prev 0/064A9748, desc: PRUNE snapshotConflictHorizon: 6409, nredirected: 0, ndead: 1, blkref #0: rel 1663/5/2610 blk 0 FPW
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064ACD40, prev 0/064AAE80, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: Heap2 len (rec/tot): 60/ 7348, tx: 0, lsn: 0/064ACD78, prev 0/064ACD40, desc: PRUNE snapshotConflictHorizon: 6409, nredirected: 0, ndead: 3, blkref #0: rel 1663/5/1249 blk 56 FPW
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064AEA48, prev 0/064ACD78, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064AEA80, prev 0/064AEA48, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/064AEAB8, prev 0/064AEA80, desc: CHECKPOINT_ONLINE redo 0/64AEA80; tli 1; prev tli 1; fpw true; xid 0:6476; oid 161285; multi 1; offset 0; oldest xid 722 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 6476; online
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064AEB30, prev 0/064AEAB8, desc: RUNNING_XACTS nextXid 6476 latestCompletedXid 6475 oldestRunningXid 6476
rmgr: Heap len (rec/tot): 317/ 3389, tx: 6476, lsn: 0/064AEB68, prev 0/064AEB30, desc: HOT_UPDATE old_xmax: 6476, old_off: 31, old_infobits: [], flags: 0x14, new_xmax: 0, new_off: 32, blkref #0: rel 1663/27783/95758 blk 0 FPW
rmgr: Transaction len (rec/tot): 46/ 46, tx: 6476, lsn: 0/064AF8A8, prev 0/064AEB68, desc: COMMIT 2025-04-12 10:21:48.755004 BST
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064AF8D8, prev 0/064AF8A8, desc: RUNNING_XACTS nextXid 6477 latestCompletedXid 6476 oldestRunningXid 6477
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064AF910, prev 0/064AF8D8, desc: RUNNING_XACTS nextXid 6477 latestCompletedXid 6476 oldestRunningXid 6477
rmgr: XLOG len (rec/tot): 114/ 114, tx: 0, lsn: 0/064AF948, prev 0/064AF910, desc: CHECKPOINT_ONLINE redo 0/64AF910; tli 1; prev tli 1; fpw true; xid 0:6477; oid 161285; multi 1; offset 0; oldest xid 722 in DB 1; oldest multi 1 in DB 1; oldest/newest commit timestamp xid: 0/0; oldest running xid 6477; online
rmgr: Standby len (rec/tot): 50/ 50, tx: 0, lsn: 0/064AF9C0, prev 0/064AF948, desc: RUNNING_XACTS nextXid 6477 latestCompletedXid 6476 oldestRunningXid 6477
Here’s a glimpse into what WAL entries related to a user transaction might look like using pg_waldump. Note that this is just a subset; pg_waldump doesn’t display all the details.
How do we consume CDC? First naive attempts
The question, then, is: how do we access changes recorded in WAL? Can we subscribe to the event stream somehow, instead of tinkering directly with the binary WAL format?
This is when logical replication comes into play. For the consumer of user data change events - in our case Debezium -
logical replication does all the heavy lifting for us, especially by interpreting WAL contents using the pgoutput plugin
in a more structured and digestible format.
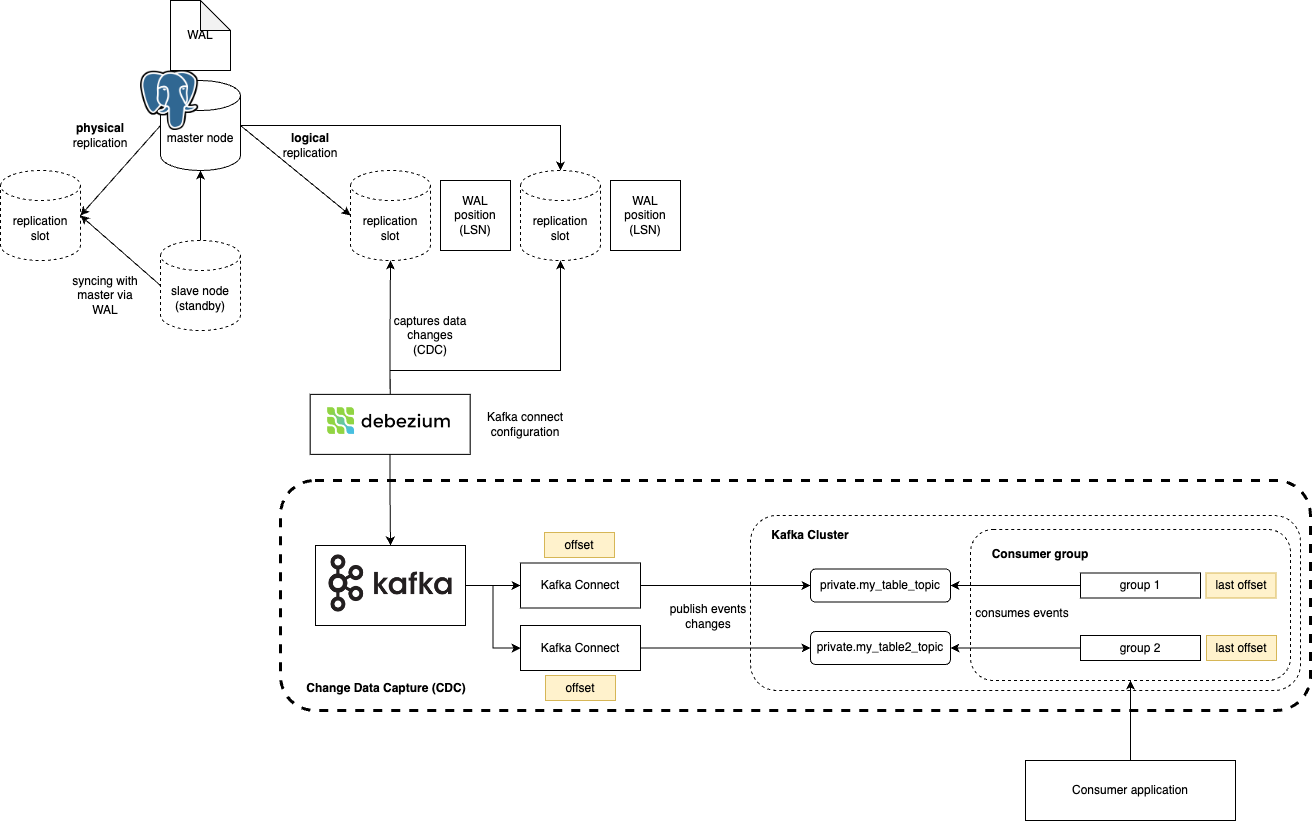
As a logical replication subscriber, we create a publication where we specify which tables we would like to monitor.
Somehow, the PostgreSQL replication engine also needs to keep track of what events were already processed by the given publication. This ensures PostgreSQL doesn’t discard WAL files prematurely before the subscriber has consumed them. Each subscriber receives changes via a replication slot. While creating a subscription (the client-side counterpart to a publication) often triggers slot creation, the publication itself doesn’t automatically create the slot. The slot ensures the server knows how far the subscriber has progressed.
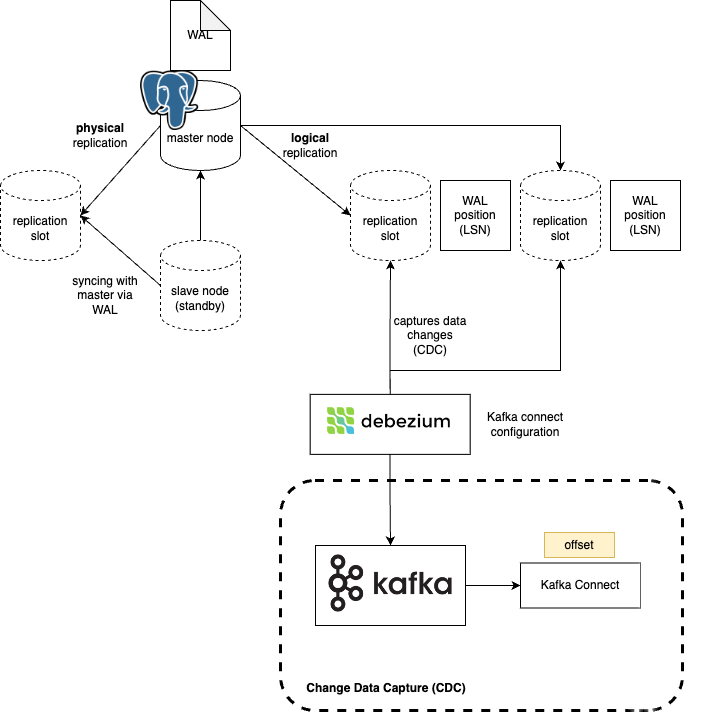 Logical replication in the context of CDC. Source.
Logical replication in the context of CDC. Source.
{kind=link}
Before we jump into creating the first replication publication, let’s make sure that our PostgreSQL instance fully supports CDC.
Configuring the PostgreSQL server
If your PostgreSQL instance doesn’t already have CDC enabled, Let’s look at which configuration parameters are crucial for enabling/optimising CDC. Please note this only serves as an overview; always consult the relevant parts of the official PostgreSQL documentation to get the most up-to-date information.
Critical Parameters
wal_level
- WAL logging detail level.
- Options:
minimal- Basic crash recovery onlyreplica- Supports WAL archiving and replicationlogical- More extensive logging, required by CDC
- Note: changing this parameter requires a PostgreSQL server restart.
max_replication_slots
- Sets the maximum number of replication slots the server can support.
- Each logical replication consumer (like Debezium) requires a dedicated slot.
max_slot_wal_keep_size
- Defines maximum amount of WAL retained when a consumer falls behind.
- Default value:
-1(no limit). - Warning: the default setting can lead to unbounded disk usage if subscriptions are left unconsumed.
wal_keep_size
- Specifies minimum size of WAL logs kept in
pg_waldirectory for standby servers. In other words, this sets a PostgreSQL’s server tolerance in respect to slowest consumers. - Prevents standby servers from needing to fetch archived WAL files if slightly behind.
- Recommendation: Set higher in high-traffic databases where replicas might lag; default may be insufficient for busy production systems.
WAL Archiving Parameters
These settings are only relevant in case you’ve decided to continuously archive your WALs, e.g. using wal-e.
archive_mode
- Options:
off- No archiving.on- Archive only in primary mode. Recommended for most WAL archiving tools.always- Archive in both primary and standby modes.
archive_command
- Specifies the command executed when archiving a WAL segment.
- Example:
cp %p /path/to/archive/%f - Security Note: Avoid putting sensitive information directly in
postgresql.conf; use environment variables with tools likeenvdirinstead.
archive_timeout
- Forces PostgreSQL to switch to a new WAL segment after specified seconds.
- Ensures unwritten data is archived regularly, even during low activity periods.
Here is what my postgresql.conf looks like for a Raspberry Pi server with low traffic:
1
2
3
4
5
6
wal_level = logical
max_wal_size = 1GB
min_wal_size = 80MB
max_wal_senders = 10
max_replication_slots = 10
max_slot_wal_keep_size = 2GB
Creating the first CDC subscription
We’re now ready to set up a publication for the hive table.
First of all, let’s create a dedicated debezium user which will be used solely for the purposes of CDC consumption. We will also grant this user the
REPLICATION permission and create a replica under the privileges of this newly created CDC user.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
DO $$
DECLARE
wal_level text;
BEGIN
-- Get current WAL level setting
SELECT current_setting('wal_level') INTO wal_level;
-- Create debezium role if it doesn't exist
IF NOT EXISTS (SELECT FROM pg_catalog.pg_roles WHERE rolname = 'debezium') THEN
CREATE ROLE debezium WITH LOGIN PASSWORD 'changeme' REPLICATION;
GRANT USAGE ON SCHEMA outbox TO debezium;
GRANT SELECT, INSERT, UPDATE, DELETE ON ALL TABLES IN SCHEMA outbox TO debezium;
GRANT USAGE, SELECT ON ALL SEQUENCES IN SCHEMA outbox TO debezium;
-- Force password change
ALTER USER debezium WITH PASSWORD 'changeme' VALID UNTIL 'now';
END IF;
END
$$;
Very important detail: creating a publication typically requires superuser privileges or specific grants (CREATE ON DATABASE). In practice, it’s not a very good idea to create the CDC subscriber as a superuser just because we need to create a publication for it; instead, consider creating the replication publication using an existing superuser and always limit the permissions of the CDC user
as much as possible.
Sanity check
We can verify that the publication was created using SELECT * FROM pg_publication;.
Replication slots can be checked using SELECT * FROM pg_replication_slots;.
This is all what is required from our side. We will need to pass the replication slot to Debezium, so make sure you have the slot name handy.
What about performance?
For use cases such as feeding data lakes or continuous database replication, it might be tempting to create a publication covering all tables (FOR ALL TABLES). This is potentially problematic for several reasons:
- I/O strain: Logical replication adds overhead. High transaction volumes mean WAL segments are generated and must be processed/decoded frequently, increasing I/O load.
- Disk space issues: If a consumer (like Debezium) lags significantly, the replication slot will retain WAL files needed by that consumer. This can lead to the
pg_waldirectory filling up disk space, potentially crashing the server. Alternatively, ifmax_slot_wal_keep_sizeis set and exceeded, the slot might be invalidated, forcing the consumer to reinitialize. - Logical decoding overhead: While
pgoutputworks over an efficient binary WAL format, it could still pose a noticeable overhead with large enough traffic.
⚠️ Limitations and drawbacks
Initial snapshot pain
When you set up a Debezium connector for the first time, you have two main modes of operation: no_data, which basically fetches database model and listens for new changes, or initial, which performs a snapshot of the current table data first and then transitions to streaming subsequent changes recorded in the WAL.
initial mode might be necessary, so you have to make sure that deploying Debezium for the first time will not bog down your production.
WAL has limited size and therefore limited history memory
The limited size of WAL is something you always have to work with. Changes older than the retained WAL segments won’t be available directly via logical replication. If you need a complete history beyond the retained WAL, you’d typically rely on restoring from a base backup and applying archived WAL files, a separate - and needless to say, much more painful - process from live CDC streaming.
Consumer must perform well
The consumer must keep pace to prevent WAL accumulation on the primary server to avoid potential disk space exhaustion or slot invalidation (if max_slot_wal_keep_size is configured and exceeded).
In a way, we tightly couple the PostgreSQL server’s operational health (disk space, performance) with the consumer’s availability and performance, which in some cases might be really cumbersome, impractical or even dangerous (on-demand infra, systems which are not online 24/7, etc.).
Imbalanced traffic databases require special care
One of the pains which might not be obvious or even present right from the start are databases where traffic flows through various tables differently. For example, you might manage near-to-static tables alongside high-traffic tables (like user event logs) updated thousands of times per second.
Monitoring high-traffic tables is usually straightforward. However, monitoring low-traffic tables alongside them can be tricky, as described in detail by a PayU engineer in a Medium article.
In short, if a monitored low-traffic table hasn’t changed in a long time, the WAL LSN (Log Sequence Number) Debezium needs to resume streaming for that specific table might reference a WAL segment that has already been recycled due to high activity on other tables. This can cause errors or require Debezium to use workarounds (adjusting heartbeat intervals) to re-synchronize, as it can’t find its expected starting point in the available WAL stream.
Outbox pattern
In this article, you learned the key principles of CDC.
In microservices and similar setups, there is one more topic to cover: ensuring all CDC changes eventually reach the end consumers.
We can use the Outbox pattern which is commonly used in tandem with CDC.
Summary
wal_level = logical, which enables the detailed logging needed for CDC. A server restart is usually required after applying the configuration.
- the potential performance impact of initial data snapshots when setting up CDC;
- limited WAL retention causing data loss if consumers lag too far behind;
- tight coupling between database health and consumer performance;
- special configuration needs for databases with imbalanced traffic patterns across tables.