3. Outbox pattern
Retrospective
We’re quite far in this series. By now, you should have a good understanding of how Change Data Capture (CDC) operates internally, along with its limitations and strengths. We’ve also explored database-level support for CDC, using PostgreSQL as a key example.
Now, we’ll turn our attention to a more specific application of CDC: microservices. For a motivating illustration, I highly recommend reading this Debezium article before continuing.
A fundamental challenge in distributed systems is the need for reliable information propagation across all participating services, a task that inherently involves trade-offs. If you haven’t heard of the CAP theorem, there are many excellent resources online which explain it.
Let’s revisit our fictitious beehive management system, featuring two key services: beehive-control, responsible for managing user data, especially their hives, and beehive-external, which gathers data from external sources.
beehive-external only requires a chosen subset of user data, which we can imagine as a ‘remote materialized view’ of the source data owned by beehive-control. These change data events are transferred via a message broker; in the example concluding our series, we’ll be using Redis Streams.
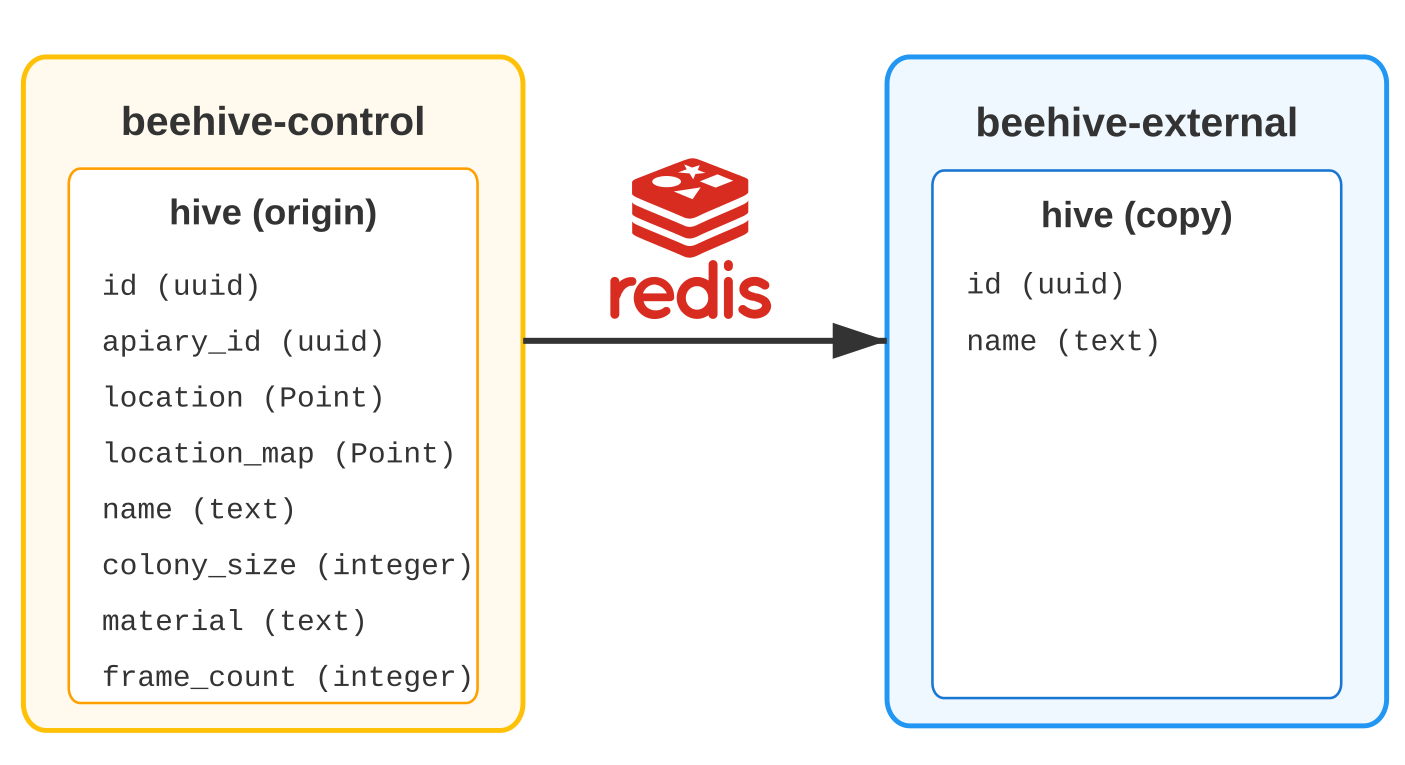
Our objective is to ensure that beehive-external is informed of any changes to the source hive table, including what exactly happened.
Simple solutions are yet again not enough!
Initially, one might consider simply capturing and publishing each change to the message broker as a complete solution. However, this approach works reliably only in ideal circumstances. We need a mechanism to ensure that changes eventually lead to a consistent state: either both beehive-control and beehive-external update their respective data stores, or neither does.
This characteristic is what distributed systems theory terms eventual consistency. It implies that while changes aren’t guaranteed to be instantaneous or atomic, the system is designed to avoid permanent data inconsistencies.
The Outbox Pattern in Domain-Driven Design (DDD)
The core principle of this approach involves having an outbox table within the data owner’s database. For our purposes, when a modification occurs in the hive table, a corresponding record is also inserted into the outbox table – crucially, as part of the same database transaction.
Important terminology note: the Outbox pattern is firmly rooted in the principles of Domain-Driven Design (DDD), which itself operates independently of relational table concepts. DDD places significant emphasis on the ubiquitous language – a shared vocabulary specific to the business domain – which defines fundamental units of information known as aggregates. Changes to these aggregates are then persisted as an event stream, a concept often synonymous with event-driven architecture within the DDD context.
Here is what an outbox table typically looks like:
1
2
3
4
5
6
7
CREATE TABLE outbox (
id uuid NOT NULL,
aggregate_type varchar(255) NOT NULL,
aggregate_id varchar(255) NOT NULL,
type varchar(255) NOT NULL,
payload jsonb NOT NULL
);
| Column | Description |
|---|---|
id |
Unique identifier visible to consumers for managing duplicate messages. |
aggregate_type |
Root aggregate type in DDD (e.g. hive). May vary based on domain complexity. |
aggregate_id |
Reference to the specific modified aggregate instance. |
type |
Event type (e.g. HiveEstablished). Avoid CRUD-like types per DDD principles. |
payload |
Type-agnostic field for event data. Eliminates need for multiple outbox tables per aggregate. |
For every change we want to propagate, we will also write a corresponding new row to the outbox table within the same transaction. This outbox table is then monitored – using CDC in our scenario – and its contents are published to downstream consumers.
We will define our beehive system aggregates in the concluding article.
Outbox pattern downsides
Now, let’s turn our attention to most common concerns.
Unlimited outbox table size
The mechanism described so far overlooks a crucial detail: the outbox table could potentially grow indefinitely with each new event.
We have two primary strategies that address this issue:
- Immediate deletion: The entry in the
outboxcan be deleted immediately as part of the same transaction that inserted it. (The rationale for this approach is detailed below.) - Delayed deletion: The entry can be manually deleted only after the consuming service acknowledges the change, or alternatively, the row can be deleted after a fixed time period, whichever happens first.
The reason why option 1 can be effective is that, while no persistent rows will be visible in the outbox table, it’s important to remember that before committing any modifications to user data, PostgreSQL always logs all changes to the WAL. Consequently, Debezium can still capture these changes even if no physical record persists in the outbox.
However, I personally think that this approach does more harm than good because:
- It is inherently awkward to debug; remember, there would be nothing in the
outboxtable. - There’s no assurance that Debezium will capture all changes, particularly in high-throughput environments where the Write-Ahead Log (WAL) might be overwritten rapidly. Admittedly, this is more of a problem of an unsuitable PostgreSQL or Debezium setup, but this point nevertheless does underline the debugging problem above.
- We have no mechanisms to verify if a client has processed a message.
- This may be indeed desirable, as we want to have as decoupled an architecture as possible. My criticism is more towards the fact that we can’t even consider such a possibility with this implementation.
- Replay of events can be a relatively tedious operation.
The second strategy addresses these concerns, albeit potentially introducing more architectural coupling, especially if we choose to and are able to implement client acknowledgements.
Handling Potential Debezium Failures
In an ideal scenario, upon restarting after a failure, Debezium will resume processing from its last known position (typically by referencing the replication slot) and catch up on any missed changes.
What if Debezium lags too much behind?
This becomes a significant concern primarily if we decide for the immediate deletion of entries from the outbox table; the rationale for this should be clear by now. In such cases, reinitializing Debezium might be the only viable solution. With delayed deletion, we can add a mechanism similar to a dead-letter queue redrive, though explaining it in detail is beyond this article’s scope.
Handling Message Broker Failures
The direct answer is: handling this is your responsibility. This is where complexities can arise, particularly if you choose not to use Kafka Connect which has mechanisms to handle outages. You would then need to design a solution, potentially a custom one, tailored to your specific sink (=the destination to which Debezium sends CDC events).
Reliable information propagation
How do we know the message was really processed? This is an aspect where the Outbox pattern, in its standard form, doesn’t provide a direct solution, as it wasn’t originally intended for this purpose. It offers the fundamental structure, but the responsibility of implementing additional tracking or bookkeeping mechanisms on the outbox owner’s side falls upon us.
One idea might be to have an async command channel through which subscribing services can send confirmation messages to the outbox owner once they’ve successfully processed an event, indicating that it is safe to delete the corresponding outbox entry.
To conclude our series, let’s proceed to putting everything to practice.