1. Introduction to CDC
What is CDC?
Business-critical data often serve purposes beyond their primary use by customers. You’ll often need to propagate data changes to other systems for various use cases, such as: cache management, real-time BI dashboards, centralized data lakes, I’m sure you can name a few more.
Change Data Capture (CDC) can be very helpful in such scenarios. CDC is a process that involves observing or listening to data changes at their source, extracting these changes, and then making them available in a unified format. By reliably reacting to data changes in real time, CDC enables a more decoupled, asynchronous, and fault-tolerant architecture.
Debezium is an open-source distributed platform that implements CDC. It acts as a bridge by capturing changes from various database vendors, such as MySQL, PostgreSQL, MongoDB, and many other supported connectors. These changes are then streamed as a series of events, often using a message broker like Kafka. Debezium simplifies the inherent complexities of CDC.
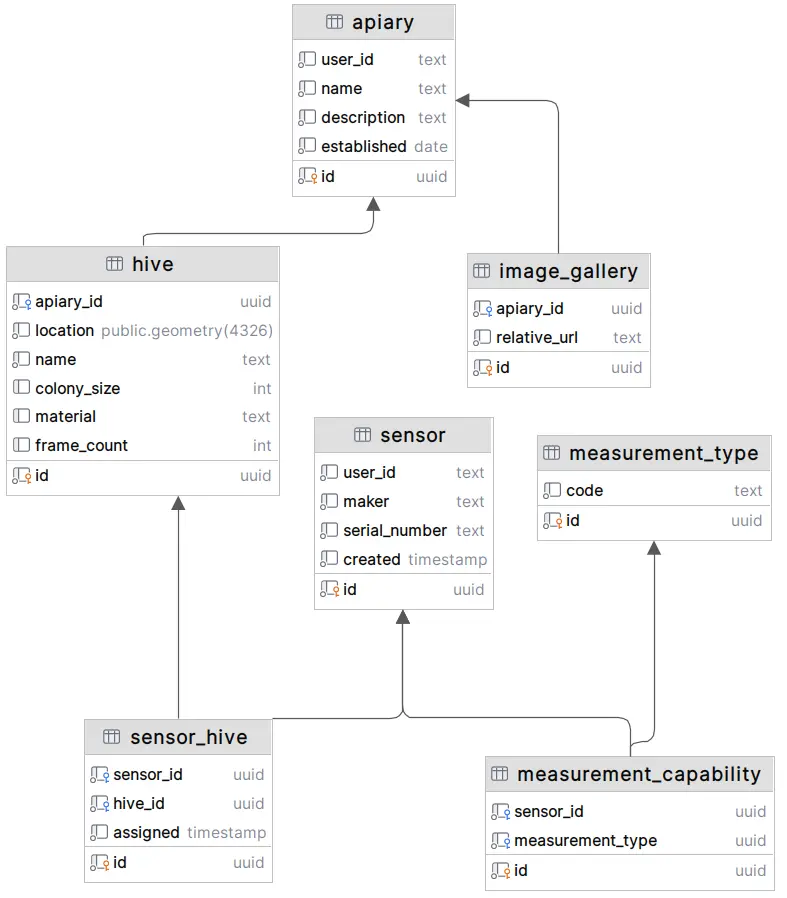
In this series, we will demonstrate the principles of Debezium on a very simplistic data model: a fictitious beehive management system. For all of our examples, we will use PostgreSQL as the database source, so your mileage may wary. Here is what the data model looks like:
What can we do instead of CDC
Consider a scenario where we need to monitor changes in the hive table, which is central to our application. Let’s begin with the most naive and easy-to-implement ways first.
1. Auxiliary columns directly in hive
What you might have encountered or have used yourself is using timestamp columns like created and updated. Their values can be either set using application logic or with the help of the database. Usually, you would do this using SQL triggers, something like:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
ALTER TABLE hive.hive
ADD COLUMN created TIMESTAMP NOT NULL DEFAULT NOW(),
ADD COLUMN updated TIMESTAMP NULL;
CREATE OR REPLACE FUNCTION update_modified_column()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated = NOW();
RETURN NEW;
END;
$$ LANGUAGE plpgsql;
CREATE TRIGGER update_hive_modified
BEFORE UPDATE ON hive.hive
FOR EACH ROW
EXECUTE FUNCTION update_modified_column();
This approach ensures that regardless of who modifies any row in the table, we will always know its creation timestamp and the last modification time.
Pros
| Benefit | Description |
|---|---|
| Consistency | Automatically maintains data integrity regardless of how data is modified. |
| Reliability | Cannot be bypassed or forgotten by application code. |
| Low Effort | Triggers are straightforward to implement with basic RDBMS knowledge. |
| Availability | Works with virtually any database vendor - triggers are universally supported. |
Cons
| Drawback | Description |
|---|---|
| Magic Logic | Behavior happens “invisibly” on the database side, potentially confusing developers. |
| Performance Cost | Adds processing overhead, especially problematic with batch modifications. |
| Vendor Differences | Trigger syntax and capabilities vary significantly between database systems. |
| Limited Auditing | Lacks details about what changed, how frequently, and which data was modified. |
| SRP Violation | Adds non-domain columns to data models, potentially creating security concerns. |
2. Dedicated audit table
We can address some of the issues associated with using ‘embedded audit columns’ by creating a separate audit table, as shown below:
1
2
3
4
5
6
7
8
9
10
11
CREATE TABLE IF NOT EXISTS hive.hive_audit
(
audit_id SERIAL PRIMARY KEY,
hive_id uuid NOT NULL,
changed_at TIMESTAMP NOT NULL DEFAULT NOW(),
changed_by text DEFAULT current_user,
operation text NOT NULL CHECK (operation IN ('INSERT', 'UPDATE', 'DELETE')),
column_changed text,
old_value text,
new_value text
);
We can then create a corresponding trigger which will populate hive_audit on execution. The trigger logic might become very nasty to maintain and debug, though (not mentioning schema changes). Nevertheless, we would now get much more detailed information about what is happening in the hive table and we have separated concerns correctly.
The main issues with this solution, though, are DB performance and disk usage, since it’s not impossible that the hive_audit table would be bigger than the source hive table itself.
If you’re working with tables that don’t change frequently, this approach might be sufficient.
3. Periodic change ingestion
An audit table itself can be a very helpful diagnostic tool but if other components need to know when something changes, they usually can’t access the database directly. In such scenarios, a background or scheduled process could periodically check for changes in the updated column (or the hive_audit table) and notify other systems.
The main problem here is that you’re still relying on those first two methods, and both need you to be able to change the database model. That can be problematic especially for legacy systems. And, as you might imagine, the periodic process will put yet another strain on the database, which is usually already under nontrivial load in production.
We can circumvent this by scheduling the processor outside of peak hours but that poses another problem in case we only have the created/updated fields at hand - inevitably, there are changes which we could miss, including row deletions.
4. Honourable mention: wal-e et al.
Internally, PostgreSQL makes heavy use of a write-ahead log (WAL), which is basically a TODO list for the PostgreSQL engine. Any change to be propagated to the database is written first to this log and only then is committed to the database itself.
So, in essence, WAL can be used to reconstruct the whole database from the very start. The practical issue with WALs, though, is that they can grow very fast, so in practice, WAL files are usually truncated only to a certain size and, as a result, contain changes only back to a certain point in time.
wal-e, a utility written in Python, overcomes this issue by continuously spilling the WAL contents to an external storage, such as S3.
We will further discuss caveats associated to working with WALs later.
CDC
Sometimes, simple solutions might not be enough. Business requirements (e.g. in FinTech), legislation, or the needs of data analytics teams might require continuous, reliable, and detailed processing of all changes in the master database(s). As indicated, that’s when we can make use of CDC.
As already mentioned, CDC is a very universal tool which can be used for variety of reasons and use cases, for example:
- continuous data replication
- cache management
- data change propagation in a distributed service architecture (microservices)
- auditing
- data lakes
- normalization of data sources (into one, universal Kafka Connect format)
- legacy system migration
Disclaimer: it is important to mention that CDC is in 2025 still a relatively new concept, so make sure to research what possibilities you have for your specific setup.
Why Debezium
At the time of writing, Debezium seemed a pretty solid choice for CDC. Here are a few reasons why:
✅ Active Red Hat support
Even though it is fully open-source, Debezium is primarily developed and supported by Red Hat. This means the project has reasonable funding and a roadmap. For me personally, that is one of the most crucial criteria when choosing a piece of software which is intended to be used in production.
✅ Proven by others
Debezium has been already used at massive scale in companies you might have heard of:
✅ Wide range of data source support
See a list of currently supported data sources.
✅ Flexible deployment options
There are three ways you can use Debezium:
- As a library embedded into the application
- As a standalone server, built on top of Quarkus
- Using Kafka Connect which is the recommended option, especially in case you already use Kafka in your infrastructure
Why NOT Debezium
As you might expect, there are also instrinsic issues you might come across when using - and especially relying on - Debezium or CDC in general.
⚠️ In case something goes wrong, you’re on your own
To be clear: while the Debezium documentation and community are open and high-quality, if you don’t have a database admin readily available, getting started can be challenging.
The main added value of Debezium is transaction log parsing and streaming. However, this also comes with caveats: it puts a load on the development and/or operations team. Deploying Debezium requires a very good understanding of how the database server is set up and the possible specifics that come with it (physical system resources, database sizes, …).
This might be a deal-breaker especially for small development teams.
⚠️ (Yet another) additional infrastructure
This partly relates to the previous point: setting up Debezium in production will most likely require setting up additional infrastructure. But then again, if you find yourself in a situation when you contemplate using CDC, you can most probably afford rationalizing the extra cost (inluding the time of your development team!).
⚠️ Duplicate handling
A well-known and well-documented downside of using Debezium is that changes are propagated to clients at least once, not necessarily exactly once. Therefore, it is expected that the consumer handles duplicates explicitly.
⚠️ DB monitoring is practically mandatory
In case you’re not doing it already, enabling CDC can have a performance impact, so monitoring the database health and especially its disk usage is crucial. This might again be problematic with legacy systems or systems you have limited access to.
Other CDC products
- enterprise-ready heavy machinery such as Qlik or GoldenGate
- Apache Nifi
- Google Datastream
- Estuary Flow
- Amazon DMS is kind of a viable choice as it integrates nicely with an existing AWS project
- one of the main advantages is the possibility to switch to CDC at a particular point in time (i.e. the setting can be turned on even after the RDS is created)
- filtering options are sparse, though, compared to many Debezium routing and filtering strategies
- most importantly, DMS was designed for one-off DB migrations, not as a CDC product :)
- Fivetran
- I haven’t explored it thoroughly but integration with cloud is not exactly fortunate as the first AWS tutorial on their website orders you to enable public access to your RDS - yuck!
Next, we will look into how CDC works behind the scenes in the case of PostgreSQL.
Summary
CDC is a technique to monitor, capture, and share data changes from a source (like a database) in near real-time. This allows other systems to easily process to such changes.
Simpler methods like timestamp columns or audit triggers often lack detail about what changed or can heavily impact database performance. CDC tools like Debezium typically read database transaction logs, offering a more efficient, detailed stream of all changes, often without altering source tables.
Implementing Debezium requires database expertise, adds infrastructure complexity (Debezium, possibly Kafka), means downstream applications must handle potential duplicate events ("at-least-once" delivery), and necessitates careful monitoring of the source database's performance and resource usage.